Limitations of ASR Speech Recognition Today
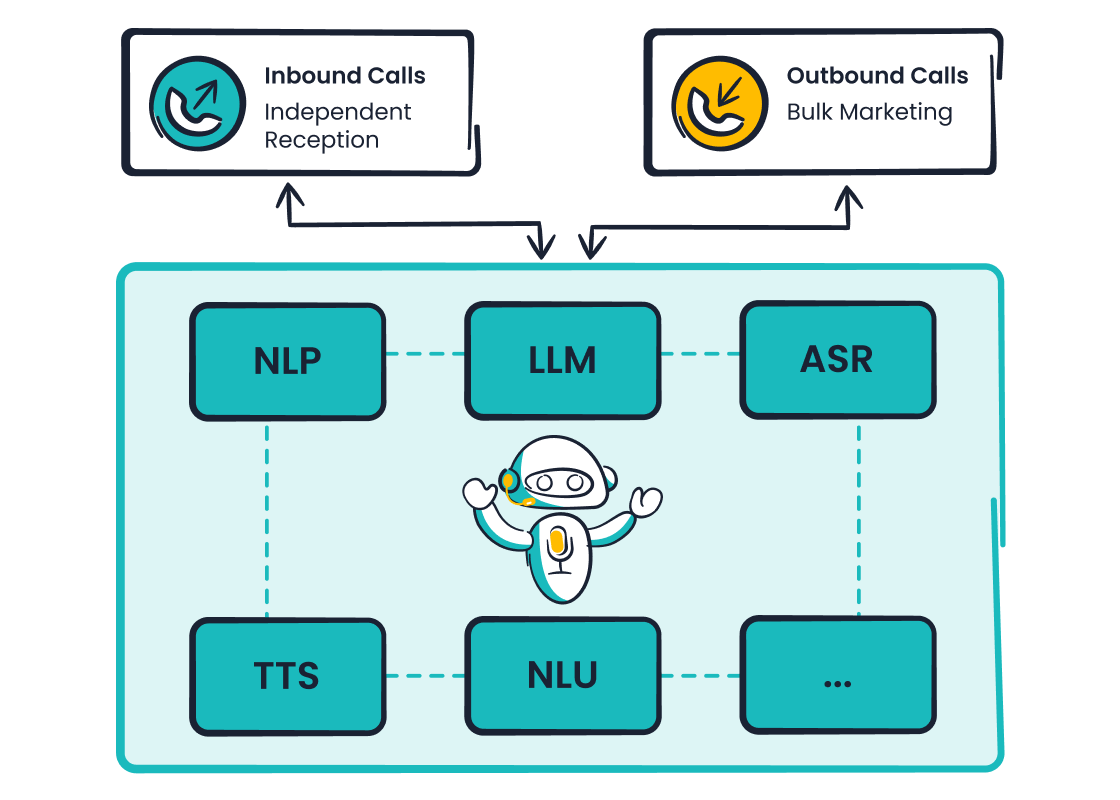
The global Automatic Speech Recognition (ASR) Software market is projected to reach USD 5.2 billion in 2024, making the technology seem like a solved problem. If ASR is so advanced, why do frustrating transcription errors still happen in customer service calls? Poor speech recognition can affect even an advanced Sobot call center. These inherent limitations prevent perfect accuracy. The core ASR challenges impact all systems, from basic tools to platforms like Sobot that leverage Sobot AI. This is the reality for asr speech recognition today.
Environmental Limits of ASR Speech Recognition
An ASR system’s accuracy often depends on the environment where speech is captured. The ideal quiet room is rare in real-world customer service scenarios. Physical surroundings introduce variables that can significantly degrade recognition performance.
Background Noise and Crosstalk
ASR systems struggle to isolate a primary speaker’s voice from background noise. This is a common problem in busy call centers or when customers call from public locations. The ASR must distinguish the intended speech from many other sounds.
Common Sources of Noise Pollution for ASR:
- Agent-related noises: Sounds from the office, like coworker conversations and keyboard clicks, can interfere with the audio.
- Noisy customer environments: Customers often call from cars, airports, or cafes with loud background chatter and announcements.
- Technical interferences: Equipment like air conditioning units or network static can add disruptive noise to the call.
These competing sounds make it difficult for the technology to achieve accurate recognition.
Poor Audio and Data Compression
Low audio quality presents another major obstacle. A heavily compressed audio file is like a blurry photo; the ASR system loses critical details needed for analysis. Traditional phone networks (PSTN) digitize voice at 64 Kbps without compression, which preserves the signal but requires high bandwidth.
Modern systems often use compression to reduce file size. However, this process can negatively impact ASR accuracy. In some tests, uncompressed audio files resulted in a 7.6% lower word error rate compared to compressed versions. This shows how poor audio quality directly harms the final transcription.
Microphone Distance and Acoustics
The physical space where a person speaks creates its own set of challenges. Room echo, or reverberation, occurs when sound waves bounce off surfaces and overlap with the direct speech. This effect contaminates the audio signal, making it difficult for an ASR to process. Certain speech sounds, like nasals, are particularly vulnerable to this type of distortion.
Microphone placement is also critical. The best asr speech recognition results occur when a speaker is close to the microphone, ideally around 1 meter. As the distance increases to 4 meters or more, performance degrades sharply.
Speaker Variability in Automatic Speech Recognition
Human speech is incredibly diverse. This variability creates significant challenges for automatic speech recognition systems. An ASR model trained on one type of speech may struggle to understand another, leading to errors in transcription.
Accents, Dialects, and Non-Native Speech
Accents and dialects present a major hurdle for ASR technology. Most ASR training data comes from native English speakers, which makes it difficult for the systems to accurately process non-native accents. Studies show a significant difference in performance, with one model showing a Word Error Rate (WER) 3.40 points higher for non-native speakers. Even among native speakers, regional dialects can cause problems for speech recognition.
ASR systems work best for people from certain regions, like California. They perform worst with other dialects, such as Scottish English.
This gap in recognition accuracy highlights the need for more diverse training datasets to improve ASR performance for all users.
Specialized Jargon and Proper Nouns
Every industry has its own unique language. Generic asr speech recognition models often fail to understand this specialized terminology. This can cause major issues in fields where precision is critical. Industries with challenging jargon include:
- Medicine
- Law
- Technology
Proper nouns, like brand names or unique places, are also a common source of errors. These words are often out-of-vocabulary (OOV) for a standard ASR model because they do not appear in general training data. An ASR system might misinterpret a brand like 'Duane Reade' or a location like 'Astoria' because it lacks the necessary context for accurate recognition.
Natural Speech Patterns and Disfluencies
People rarely speak in perfect sentences. Natural conversation includes filler words, repetitions, and pauses. An ASR must decide how to handle these disfluencies. For example, filler words like "um" and "ah" can be removed or transcribed, and different ASR services handle them differently. Some systems automatically remove repeated words, while others transcribe them exactly as spoken. These choices directly impact the final transcript's accuracy and readability, affecting how well the system captures the speaker's true intent.
Inherent System and Contextual ASR Constraints
Beyond environmental and speaker issues, automatic speech recognition technology has fundamental system-level constraints. An ASR system's core design relies on patterns from its training data, not genuine comprehension. This dependency creates significant hurdles for accurate speech recognition.
Lack of True Contextual Understanding
An ASR system excels at converting audio into text. However, it does not truly understand the meaning behind the words. This lack of contextual awareness causes errors when human listeners would easily grasp the intent. For example, an ASR can struggle to differentiate between words that sound the same but have different meanings.
Common Homophone Errors in ASR:
- An ASR might transcribe "their" when a speaker says "there."
- It may confuse "to," "too," and "two" without sentence context.
This limitation extends to complex human communication like sarcasm or idioms. The ASR processes the literal words, missing the underlying sentiment. This can lead to incorrect analysis in customer service interactions.
| Limitation Type | Impact on ASR Effectiveness |
|---|---|
| Sarcasm Detection | Positive-sounding feedback with negative intent skews results. |
| Idiomatic Expressions | Literal interpretation of idioms like “not my cup of tea.” |
Training Data Dependency and Bias
The performance of asr speech recognition is entirely dependent on its training data. An ASR model learns to recognize speech patterns from the vast audio library used for its training. If the training data is limited or biased, the model's accuracy suffers. Extensive training is necessary for robust performance.
This reliance on training means the system may fail to recognize words or accents not well-represented in its training set. The quality and diversity of the training are paramount. A model with insufficient training on medical terms will perform poorly in a healthcare setting. Similarly, a system with limited training on regional dialects will struggle with those speakers. Continuous training and refinement of the training data are essential for improving the ASR model's capabilities and overcoming these inherent biases. The training process defines the boundaries of what the ASR can accurately recognize.
Overcoming ASR Limitations with Advanced Solutions
Modern technologies offer powerful ways to overcome the inherent limits of basic ASR. Advanced solutions move beyond simple transcription. They use a deeper level of intelligence to interpret speech, improving both accuracy and overall system performance. This leads to a better customer experience.
The Role of Advanced Voicebots

Advanced voicebots represent a significant leap in performance. They use Natural Language Processing (NLP) and Large Language Models (LLMs) to understand user intent. Unlike traditional systems that just convert audio to text, these bots analyze context. Sobot's Voicebot, for example, leverages these technologies for more human-like interactions. This approach improves transcription accuracy. It also helps overcome challenges with specialized jargon and natural speech patterns. Continuous training ensures the system's performance adapts and improves. This training refines its understanding, leading to better transcription and higher accuracy. The ongoing training boosts the bot's performance.
AI-Powered Platforms for Customer Service
Comprehensive AI-powered platforms provide a complete answer to ASR challenges. A platform like Sobot's AI Solution offers features designed to tackle speaker variability. Multilingual support is a key component. It helps address accent and dialect issues that often lower transcription accuracy. The system's training includes diverse language data. This extensive training improves its performance across different user groups. Better training results in more reliable transcription. The platform's performance depends on the quality of its training. This focus on inclusive training directly boosts transcription accuracy and overall performance.
Integrating Human-AI Collaboration
Combining artificial intelligence with human oversight creates a powerful synergy. This integration is key to improving first-contact resolution and operational efficiency. The online supermarket Weee! provides a clear example. The company faced challenges with language barriers and an inflexible system. They implemented Sobot's voice product to enhance their operations. The solution provided multilingual support and intelligent call routing. This integration improved agent efficiency by 20% and boosted customer satisfaction to 96% (source). This success demonstrates how targeted ai solutions and continuous training can deliver superior performance. The improved accuracy of the system's transcription was vital. This high level of performance and accuracy comes from excellent training.
ASR speech recognition faces clear limitations. Poor audio quality, diverse speaker accents, and system constraints often lead to inaccurate outputs. However, businesses can overcome these challenges. Companies like Sobot pioneer the next generation of AI solutions. By integrating advanced Voicebots and AI platforms, businesses can improve first-call resolution by up to 25%. This approach helps them conquer traditional asr hurdles, enhance customer interactions, and truly embark on a better contact journey.
FAQ
How is a modern IVR different from an old one?
A modern ivr uses AI to understand speech. A legacy ivr relies on simple button presses. This makes the new ivr much smarter. An intelligent ivr routes calls better. The advanced ivr creates a smoother customer experience by quickly solving problems.
What makes a voice user interface (VUI) effective?
An effective vui understands user intent, not just words. Good voice user interfaces use context to provide accurate responses. This makes the vui feel more natural and helpful. The system can then complete tasks correctly for the user.
Can an ASR engine be improved over time?
Yes, an asr engine can improve. Its performance gets better with continuous training on diverse audio data. This process helps the system learn new words, accents, and speech patterns. More training leads to higher accuracy and better overall results.
Why does ASR performance vary so much?
ASR performance changes based on several factors. Background noise, speaker accents, and poor audio quality all reduce accuracy. The system's training data also creates limits. These variables explain why recognition is not always perfect in real-world situations.
See Also
Unveiling the Mechanics: How IVR Voice Recognition Software Functions
Key Capabilities: Exploring Interactive Voice Response System Software Features
A Comparative Look at Leading Interactive Voice Response Software Solutions
The Best 10 Speech Analytics Tools for Call Centers in 2024
Your Essential Guide to Call Center Artificial Intelligence Software
