Data Labeling Services for Cloud AI Tools

Data labeling is the process of applying annotations to raw data for machine learning. The accuracy of AI on cloud platforms depends on this high-quality data labeling. This data is the foundation for all machine learning data.
Up to 87% of AI projects fail, with poor data quality and incorrect data labeling identified as primary reasons. This highlights the need for precise data labeling and careful data annotation of all data.
This guide explores how custom data labeling and enrichment services for cloud AI tools, like a data labeling platform from Sobot, improve model performance for machine learning. Quality data labeling ensures the precision and recall needed for machine learning tasks like computer vision and natural language processing speech recognition. This data labeling is key for data accuracy. The data labeling process requires careful labeling for precision and recall. This data requires careful labeling. This machine learning data requires this labeling of all data. This data is critical data.
The Importance of Data Labeling for Cloud AI Tools
The importance of data labeling cannot be overstated for businesses leveraging cloud AI. High-quality, accurately labeled data is the fuel that powers sophisticated machine learning models. Without it, even the most advanced cloud platforms from Amazon, Google, or Microsoft will fail to deliver their promised ROI. Professional data labeling transforms raw, unstructured data into a valuable asset, unlocking the full potential of your AI investments.
Unlocking the Benefits of Data Labeling
Investing in professional data labeling services is a strategic choice that yields significant business advantages. The core benefits of data labeling directly address common AI project pitfalls, ensuring a smoother path from development to deployment. These services provide a foundation for success.
Key benefits of data labeling include:
- Improved Accuracy: Professional providers use experienced annotators and robust quality control processes. This expertise significantly reduces errors in machine learning models.
- Cost Efficiency: Outsourcing data labeling saves on internal costs related to hiring, training, and infrastructure. Businesses can then allocate those resources to core operations.
- Scalability and Speed: Dedicated providers can quickly scale labeling operations to handle massive datasets. This capability is crucial for meeting tight deadlines and rapidly expanding AI initiatives.
Boosting Model Accuracy on Cloud AI Platforms
The performance of any machine learning model is directly proportional to the quality of its training data. AI and ML models depend on high-quality, well-managed data to produce accurate and unbiased results. Poor quality data leads to unreliable predictions and wasted investments. High-quality data, however, enables models to perform as intended.
This principle is especially true for customer-facing AI tools like the Sobot AI Chatbot. The chatbot's ability to understand user intent and provide correct answers relies on a meticulously structured knowledge base. This knowledge base is built from carefully labeled data. Proper data labeling provides the ground truth for model training. It helps reduce bias and improves the model's ability to generalize. Accurate labeling ensures that predictions align with the actual attributes of the data, boosting overall model performance. Subpar labeling can cause poor prediction accuracy, inconsistent behavior, and unreliable decision-making.
Real-World Impact: The OPPO Story
OPPO, a leading smart device innovator, partnered with Sobot to enhance its customer service. By optimizing its knowledge base—a form of data enrichment and labeling—OPPO empowered its chatbot to handle inquiries with remarkable precision. The results speak for themselves:
- An 83% chatbot resolution rate.
- A 94% positive feedback rate.
This level of model performance on a cloud platform is not possible with poorly labeled data. It demonstrates how expert data labeling and enrichment directly translate to superior customer experiences and business outcomes. The chatbot's high accuracy and customer satisfaction are a direct result of the quality data it was trained on.
Accelerating AI Project Timelines and Deployment
In the competitive AI landscape, speed to market is a critical advantage. In-house data labeling efforts often become a major bottleneck, slowing down the entire development cycle. Building a team, creating guidelines, and managing quality control consumes valuable time and resources.
Professional data labeling services eliminate this bottleneck. They provide access to:
- Domain Expertise: Teams with industry-specific knowledge for high-quality annotations in fields like computer vision or natural language processing.
- Advanced Tools: AI-assisted platforms and automation features that streamline the labeling process, ensuring accuracy and consistency while reducing turnaround time.
- Dedicated Teams: A focused workforce that can process large volumes of data quickly, accelerating project timelines and enabling faster deployment of machine learning models.
This acceleration allows technical leaders to focus on model development and strategic initiatives rather than getting bogged down in the complexities of data preparation. The labeling process becomes a seamless part of the workflow.
Scaling AI Initiatives Without Scaling In-House Teams
As AI projects grow, so does the need for data. Scaling an in-house data labeling team to meet this demand presents significant financial and operational challenges. The costs go far beyond salaries.
Building an in-house team involves numerous direct and hidden costs:
- Personnel: Recruitment, salaries, benefits, and retention for annotators, QA specialists, and project managers.
- Technology: Licensing fees for data annotation platforms and data management tools.
- Training: Continuous investment in upskilling staff on new guidelines and compliance standards.
- Infrastructure: Expenses for office space, IT support, and security measures.
These costs add up quickly, especially in high-wage regions. Outsourcing data labeling offers a more flexible and cost-effective model. The following chart compares the estimated annual cost of a small in-house team in the US versus a team in Southeast Asia, highlighting the significant savings.
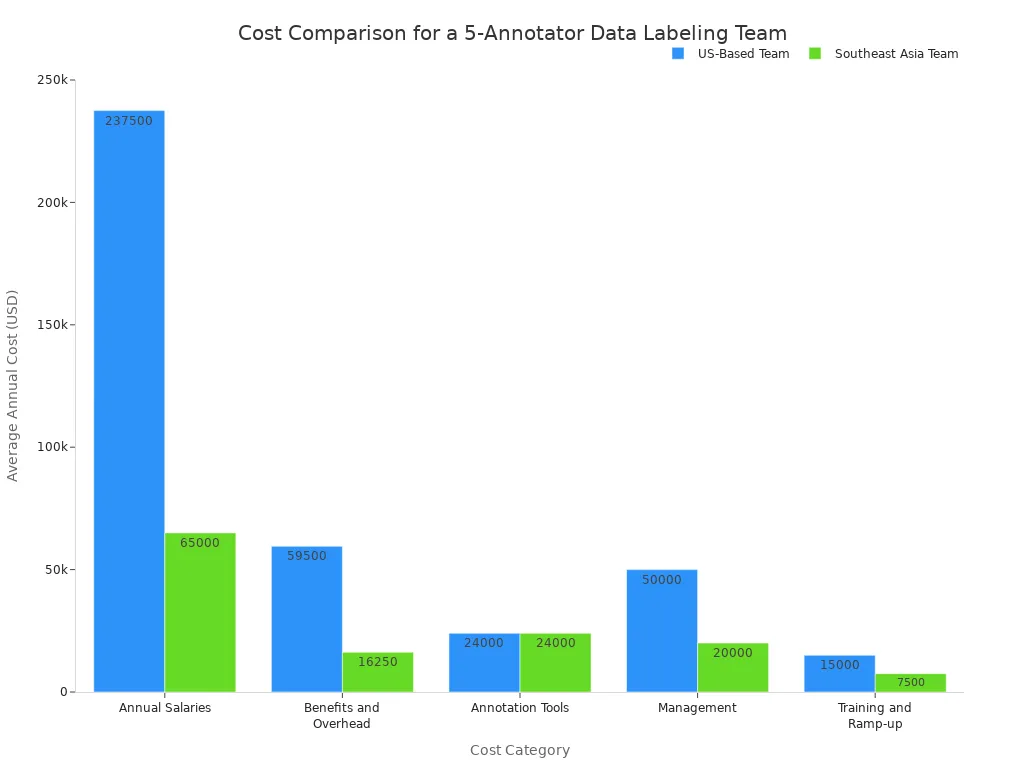
By partnering with custom data labeling and enrichment services for cloud AI tools, companies gain access to elastic workforce capabilities. They can manage sudden data spikes and large ongoing projects without the overhead of a full-time, in-house team. This approach allows businesses to scale their AI initiatives efficiently, ensuring that data labeling capacity always matches project demand without a proportional increase in headcount. This makes the entire data labeling process more manageable and predictable.
How Data Labeling Integrates into Your Cloud Workflow

Integrating professional data labeling into a cloud environment creates a seamless pipeline. This process transforms raw, unstructured data into a structured asset for machine learning. The workflow ensures data security, quality, and efficient delivery for model training. A smooth integration is key for maximizing the ROI of your cloud AI tools.
Secure Data Transfer from Cloud Storage
A secure data pipeline is the first step in the data labeling process. Professional services must integrate directly with major cloud storage solutions. This includes Amazon S3, Google Cloud Storage (GCS), and Azure Blob Storage. The goal is a frictionless flow where raw data moves from the client's cloud to the labeling service. The annotated data then flows back for machine learning training.
This transfer relies on robust security protocols to protect sensitive information.
- Secure Protocols: Secure File Transfer Protocol (SFTP) creates a protected channel for data transfer.
- Data Encryption: Advanced encryption protects data during transmission.
- Secure Access: Tools like AWS PrivateLink or Azure Private Endpoint ensure data travels through a private network, not the public internet.
The Core Data Labeling and Annotation Process
The core data labeling process turns unstructured data into high-quality data for machine learning. This workflow begins after the secure transfer of data. It involves several distinct steps to ensure precision and recall.
- Data Ingestion and Preparation: Raw data is loaded into the data labeling platform. It is then cleaned and prepared for labeling. This step is critical for tasks like computer vision and natural language processing.
- Annotation: Trained annotators apply labels to the data. They follow specific project guidelines to ensure consistency. This is where the actual data annotation happens.
- Iterative Refinement: The labeling process includes feedback loops. This helps refine annotations and improve overall data quality.
Multi-Layered Quality Assurance and Validation
Quality is the cornerstone of effective data labeling. A multi-layered approach to quality assurance (QA) ensures the highest label accuracy. This validation is essential for strong model performance. It prevents the "garbage in, garbage out" problem in machine learning.
Effective QA methodologies include:
- Consensus: Multiple annotators label the same piece of data. The system checks for agreement to ensure labeling accuracy.
- Gold Sets: A benchmark dataset with perfect annotations is used. It tests annotator performance and maintains quality standards.
- Review Stages: Expert reviewers manually check a sample of the labeled data. This final check confirms the data meets project requirements for precision and recall.
Seamless Data Delivery for Model Training
The final step is delivering the structured data back to the client. Custom data labeling and enrichment services for cloud AI tools provide annotations in formats compatible with leading machine learning platforms. This ensures the data is ready for immediate use. The delivery process is often automated to support continuous model training and retraining. This automation helps maintain peak model performance over time. This is one of the best practices for labeling speech recognition data.
Choosing Custom Data Labeling and Enrichment Services for Cloud AI Tools
Selecting the right partner for data labeling is a critical decision that directly impacts the success of your cloud AI initiatives. The ideal provider acts as an extension of your team, delivering the high-quality data needed to maximize model performance. Making an informed choice requires evaluating potential partners against key criteria, understanding different service models, and asking the right questions. This ensures your machine learning projects are built on a solid foundation.
Key Criteria: Security, Scalability, and Quality
When evaluating custom data labeling and enrichment services for cloud AI tools, three pillars stand out: security, scalability, and quality. These criteria are non-negotiable for any organization serious about deploying reliable and effective AI.
Security and Compliance Protecting your data is paramount. A trustworthy data labeling provider must demonstrate a robust security posture. This is especially true when handling sensitive information in sectors like healthcare or finance. Top-tier providers verify their commitment through industry-standard certifications and practices.
- Certifications: Look for key compliance standards that validate a provider's security framework.
- ISO 27001: Confirms the organization has a formal system for managing data security risks.
- SOC 2, Type 2: Ensures a third-party service securely manages client data based on principles of security, privacy, and confidentiality.
- HIPAA: A mandatory requirement for handling protected health information (PHI) in the United States.
- GDPR: Demonstrates compliance with European data protection laws, essential for handling data from EU citizens.
- Technical Safeguards: Beyond certifications, a provider must implement strong technical controls. This includes data encryption both in transit and at rest, strict access controls, and detailed audit trails to monitor data handling.
Scalability AI projects rarely stay small. As your data volume grows from gigabytes to terabytes, your labeling partner must be able to scale operations without sacrificing quality or speed. True scalability is built on a combination of infrastructure, processes, and workforce management.
How Providers Ensure Scalability ⚙️
- Scalable Infrastructure: Platforms built on cloud infrastructure using tools like Kubernetes can allocate resources on demand.
- Standardized Processes: Consistent Standard Operating Procedures (SOPs) for everything from onboarding to quality control ensure efficiency across global teams.
- Multi-tiered Workforce: A flexible mix of in-house experts for complex tasks and managed crowds for simpler labeling allows for cost-effective scaling.
- Advanced Tooling: AI-assisted labeling tools and automated quality checks boost annotator efficiency and throughput.
Quality The ultimate goal of data labeling is to produce high-quality data that improves machine learning model accuracy. Quality is a measure of precision and recall in the annotations. It requires a systematic approach that goes beyond simple labeling. A focus on quality ensures the final structured data is reliable and ready for training.
Comparing Service Models: Managed vs. Self-Service
Data labeling providers typically offer two primary service models: fully managed and self-service. The right choice depends on your team's in-house expertise, resources, and project goals.
-
Fully Managed Service: This is a "white-glove" option where the provider handles the entire data labeling pipeline. This includes project management, workforce training, quality assurance, and final data delivery. This model is ideal for organizations that lack in-house expertise or want to free up their internal teams to focus on core model development and strategy.
-
Self-Service Platform: This model provides access to a data annotation platform and tools, but your team manages the workforce and the labeling process. It is best suited for companies with a dedicated team of BI experts or data scientists who prefer to maintain direct control over the data annotation workflow.
Choosing the right model is a strategic decision. The following table breaks down the key differences.
| Feature | Fully Managed Service | Self-Service Platform |
|---|---|---|
| Responsibility | Provider manages the entire process | Client manages the workforce and QA |
| Expertise | No in-house expertise required | Requires in-house project managers and QA |
| Resource Focus | Frees up internal teams for strategy | Requires dedicated internal resources |
| Control | Less direct control over the process | Full control over the labeling workflow |
| Best For | Teams focused on core AI development | Teams with established data operations |
Questions to Ask a Potential Service Provider
Before committing to a partnership, technical leaders should conduct thorough due diligence. Asking specific, targeted questions about a provider's processes can reveal their true capabilities and commitment to quality.
- How do you manage quality assurance? A reliable partner should describe a multi-layered QA process, including methods like inter-annotator agreement and expert review stages.
- How do you share quality metrics with our team? There should be a transparent system for sharing metrics on accuracy, precision, and recall, often through a client dashboard.
- What happens when quality measures are not met? The provider should have a clear, structured process for incorporating feedback, making corrections, and preventing future errors.
- How involved in quality control will my team need to be? Understanding the expected level of involvement helps set clear expectations and allocate resources appropriately.
- How do you ensure consistency across large datasets? Ask for examples of their standardized guidelines and annotator training programs, which are crucial for maintaining consistency in labeling.
Accessing Expertise for Complex Data Types
Not all data is created equal. While simple image classification is straightforward, many modern AI applications rely on complex data types that require specialized domain expertise and advanced tools for accurate labeling.
LiDAR for Computer Vision Autonomous vehicles and robotics depend on LiDAR point cloud data to perceive the world. Labeling this 3D data is notoriously difficult.
The complexity of LiDAR data presents unique challenges. Annotators must make judgments to resolve ambiguity, such as identifying a pedestrian partially obscured by a parked car. This requires a combination of advanced tools and human expertise to ensure labeling accuracy and consistency.
Medical Imaging for Diagnostics AI is revolutionizing medical diagnostics, but models trained on medical images (X-rays, MRIs, CT scans) require exceptionally precise data labeling from domain experts. The best practices for labeling this data are rigorous. Annotators must understand modality-specific characteristics, navigate 3D volumetric data, and use standardized taxonomies to ensure clinical relevance. Involving certified radiologists in the review process is one of the best practices with data labeling for healthcare.
Financial Documents and Speech Recognition In fintech, machine learning models analyze documents and transactions to detect fraud, assess risk, and automate processes. This requires sophisticated labeling techniques like entity recognition and data categorization. Similarly, analyzing customer service calls for sentiment or compliance requires expert speech recognition data labeling. The process involves transcribing speech and then applying labels to the text, a task that demands high precision to capture nuances in human conversation. This level of data labeling ensures that AI models in finance deliver reliable insights.
Professional data labeling is a strategic investment for any business using cloud AI. Quality data labeling ensures the accuracy and precision needed for machine learning. AI begins with data, not algorithms. High-quality data is the foundation for high-performing AI, leading to better model performance and customer experiences with tools like Sobot's AI solutions. The labeling process for all data, including speech data, requires careful data labeling. This labeling ensures quality data for machine learning. This data labeling improves machine learning model performance. This labeling of data is critical for machine learning accuracy. This data labeling is the core of machine learning.
Embark on Your Contact Journey. Schedule a consultation to discuss your machine learning project's data needs with Sobot and explore our custom data labeling and enrichment services for cloud AI tools and our data labeling platform.
FAQ
What is data labeling?
Data labeling is the process of adding descriptive tags or annotations to raw data. This labeling process turns unstructured data into structured data. This data is then used to train AI models for tasks like computer vision and speech recognition. The labeling of this data is fundamental.
Why is data labeling important for cloud AI?
Accurate data labeling is crucial for cloud AI tools. The labeling of data directly impacts model accuracy. High-quality data and proper labeling ensure AI systems make correct predictions. This data labeling is essential for reliable computer vision and natural language processing outcomes. This data is the foundation.
What are the best practices for labeling speech data?
The best practices for labeling speech data involve several steps. First, transcribe the speech audio to text. Next, apply specific annotations to the text data. This labeling process for speech data requires careful attention to detail. This data helps train accurate speech recognition models.
How does a data labeling platform help?
A data labeling platform streamlines the entire labeling workflow. It provides tools for managing data, assigning labeling tasks, and ensuring data consistency. This platform supports various data types, including data for nlp data labeling. The data is processed efficiently through the platform for all labeling needs.
See Also
Leading AI Solutions for Enterprise Contact Centers: A Top 10
Best Speech Analytics Tools for Call Centers in 2024
Understanding Artificial Intelligence Software for Call Center Operations
Discovering the Top 10 Call Center Analytics Platforms for 2024
Exploring Call Center Voice Analytics Technology: A Comprehensive Overview